Pattern 31 / FLOW
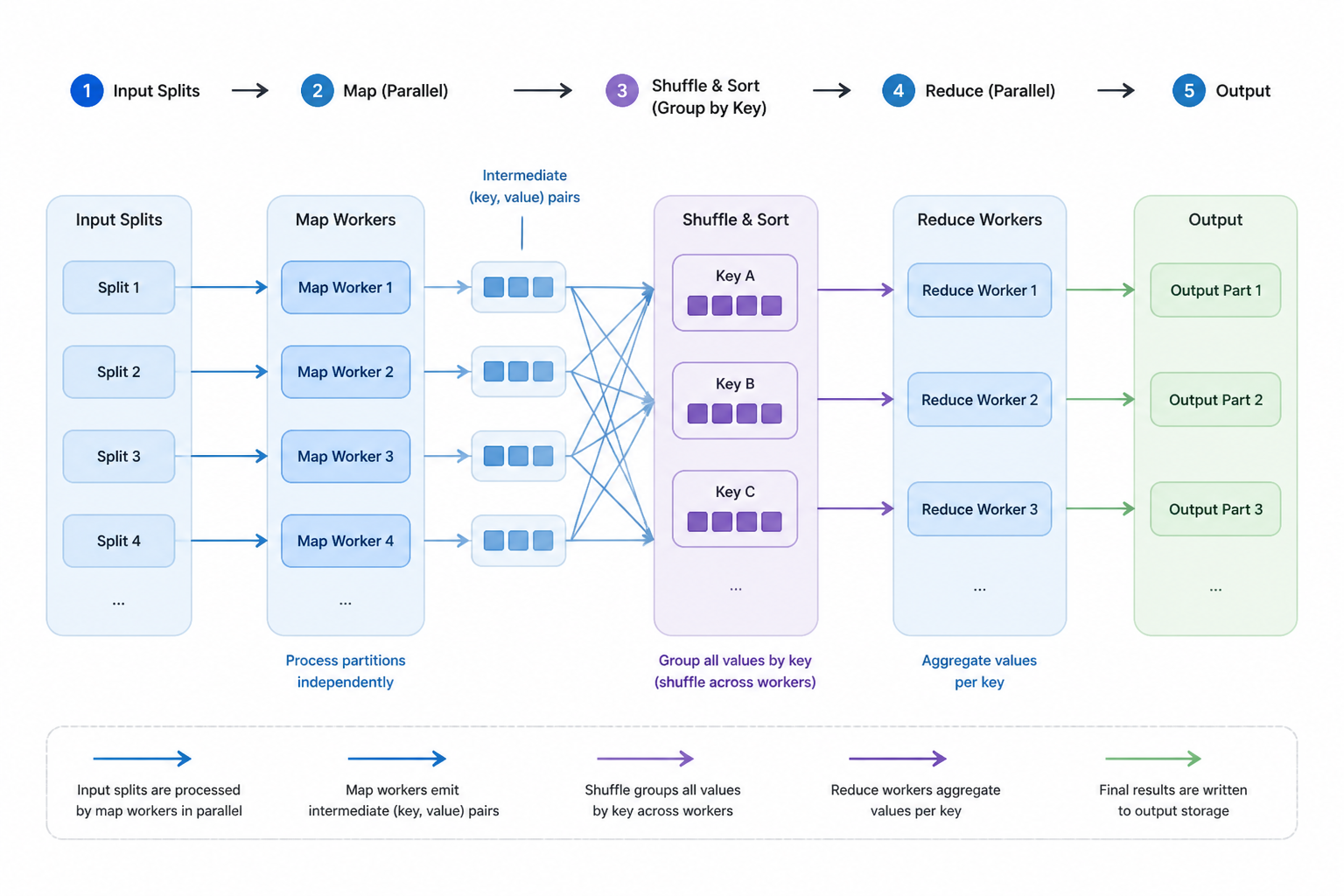
MapReduce
Use this when processing huge datasets that cannot fit on one machine.
- Pressure
- Processing huge datasets that cannot fit on one machine
- Mechanism
- Map partitions independently, shuffle/group intermediate keys, then reduce results
- Toll
- High latency and operational overhead compared with streaming for realtime needs